To illustrate the fitting and error analysis techniques of the
previous section we use them within a simple nuclear mass model. The
model expresses nuclear binding energy as a sum of the liquid drop
(LD) and shell energies [21]. The LD energy we use closely resembles the
Myers-Swiatecki LD formula [22] with symmetry terms in the volume and
surface energy parts and a modified Coulomb part. It has the form
The continuity requirements impose ![]() conditions at semimagic
nuclei, see Fig. 1. Each condition results in
conditions at semimagic
nuclei, see Fig. 1. Each condition results in ![]() linear
equations for
linear
equations for ![]() , where
, where ![]() is the polynomial order. Thus for the
second-, third-, or fourth-order polynomials (
is the polynomial order. Thus for the
second-, third-, or fourth-order polynomials (![]() =2, 3, or 4) we get
=2, 3, or 4) we get
![]() =57, 76, or 85 equations for 90, 150, or 225
parameters, respectively, resulting in 33, 74, or 130 independent
variables of the shell energy, Eq. (24). Together with the six
parameters of the liquid-drop energy, Eq. (23), the model thus
contains 39, 80, or 136 independent parameters.
=57, 76, or 85 equations for 90, 150, or 225
parameters, respectively, resulting in 33, 74, or 130 independent
variables of the shell energy, Eq. (24). Together with the six
parameters of the liquid-drop energy, Eq. (23), the model thus
contains 39, 80, or 136 independent parameters.
It should be noted that the model described above is fully linear.
This means that the iteration procedure consists of just one step,
because matrix ![]() is then constant and the convergence is
obtained after just one iteration. In this respect the simple model
considered here does not accurately resemble realistic EDF models.
However, it allows us to test and showcase all the error analysis
methods that can also be used in realistic nonlinear EDF
calculations.
is then constant and the convergence is
obtained after just one iteration. In this respect the simple model
considered here does not accurately resemble realistic EDF models.
However, it allows us to test and showcase all the error analysis
methods that can also be used in realistic nonlinear EDF
calculations.
![\includegraphics[angle=0,width=8.6cm]{fig01.eps}](img91.png)
|
We used the 1995 mass evaluation of Audi and Wapstra [15]
as our experimental nuclear binding energies. These masses are
outdated, but they serve only for illustrative purposes. The full
model with fourth-order polynomials was fitted to ![]() experimental and extrapolated binding energies of nuclei with
experimental and extrapolated binding energies of nuclei with ![]() . The resulting set of parameters was used to create metadata
masses that approximate the experimental masses with rms
deviation of 1.1MeV. In this way, we have constructed the dataset
of masses, which is exactly described by the
. The resulting set of parameters was used to create metadata
masses that approximate the experimental masses with rms
deviation of 1.1MeV. In this way, we have constructed the dataset
of masses, which is exactly described by the ![]() parameters of the
full model. Values of the LD parameters used to define the metadata
are listed in Table 1.
parameters of the
full model. Values of the LD parameters used to define the metadata
are listed in Table 1.
|
We do not ascribe any particular physical importance to the model of Eqs. (23) and (24), and we are not really concerned with the question of how well it describes the experimental data, cf. the recent discussion in Refs. [23,24]. The model only serves us for the purpose of creating the metadata, and only these metadata are the subject of the error analysis.
To the metadata given by the fourth-order model we add Gaussian noise
of a given standard deviation ![]() , i.e., random numbers are added to all of
the 2844 metadata masses. We stress here that we do not construct any
ensemble of datasets and we do not perform any ensemble averaging.
We only have at our disposal the same number of 2844
"experimental" metadata points, for which we know exactly what are
the model and noise parameters. From now on, a Gaussian noise of
, i.e., random numbers are added to all of
the 2844 metadata masses. We stress here that we do not construct any
ensemble of datasets and we do not perform any ensemble averaging.
We only have at our disposal the same number of 2844
"experimental" metadata points, for which we know exactly what are
the model and noise parameters. From now on, a Gaussian noise of
![]() MeV is used unless explicitly indicated.
MeV is used unless explicitly indicated.
The study now concentrates on repeating the least square fits of the above described second-, third-, and fourth-order models to the metadata. The fourth-order model is exact, while the second- and third-order models are inaccurate (see the discussion at the beginning of Sec 2). Note that only the metadata shell effects are imprecisely described by the second- and third-order models--the LD parts of Eq. (23) always have the same form.
Our purpose is to study the fitting procedure, values of parameters, error estimates, and confidence intervals in the situations of exact and inaccurate models. In particular, we analyze dependence of the least square fits on the weights chosen for the definition of the rms deviation. To this end, we chose weights in the form
However, it is obvious that we can equally well argue in favor of
other choices. On the one hand, for ![]() , the fit would
correspond not to fitting binding energies, but binding energies per
particle,
, the fit would
correspond not to fitting binding energies, but binding energies per
particle, ![]() , which may seem to be a reasonable choice when
discussing the LD model parameters. Naturally, this choice simply
corresponds to placing more importance in masses of light
rather than heavy nuclei. On the other hand, for
, which may seem to be a reasonable choice when
discussing the LD model parameters. Naturally, this choice simply
corresponds to placing more importance in masses of light
rather than heavy nuclei. On the other hand, for ![]() ,
heavy nuclei are considered to be more important for mass fits
than light nuclei, which can be motivated by the fact that these
nuclei are closer to the infinite-matter limit.
Obviously, these arguments cane be debated, but ultimately one has
a freedom of choice in this matter.
The parameter
,
heavy nuclei are considered to be more important for mass fits
than light nuclei, which can be motivated by the fact that these
nuclei are closer to the infinite-matter limit.
Obviously, these arguments cane be debated, but ultimately one has
a freedom of choice in this matter.
The parameter ![]() will in the following be varied from
will in the following be varied from ![]() to 1, and the value
of
to 1, and the value
of ![]() is used whenever not explicitly indicated.
is used whenever not explicitly indicated.
![\includegraphics[angle=0,width=8.6cm]{fig02.eps}](img112.png) |
We begin by discussing the influence of the Gaussian noise added to
the metadata. In Fig. 2 we show dependence of the rms
deviations of the least square fits (8) as functions of the
standard deviation of the Gaussian noise ![]() . For the exact
model, the fitting procedure reproduces the standard
deviations of the added noise perfectly well. For the inaccurate models, i.e. for
the second- and third-order polynomial fits, one obtains the rms
deviations that are higher than the added noise.
. For the exact
model, the fitting procedure reproduces the standard
deviations of the added noise perfectly well. For the inaccurate models, i.e. for
the second- and third-order polynomial fits, one obtains the rms
deviations that are higher than the added noise.
Of course, when the added Gaussian noise goes to zero, the rms deviation of the exact model also vanishes. For inaccurate models, in this limiting case the rms deviations level out and converge to about 1.6 and 1.0MeV for the second- and third-order models, respectively. One can say that the inaccurate models introduce their own intrinsic noises, which are not statistical in nature, but represent averaged inaccuracies of the models. One can see that at non-zero Gaussian noise, for inaccurate models the rms deviations are much smaller than the rms of the Gaussian and intrinsic noises. It appears that the intrinsic noise is gradually disappearing inside the Gaussian noise. This is in fact the limit, in which inaccurate models become quite good at describing less well determined experimental data.
In Fig. 3 we show the distributions of fit residuals,
![\includegraphics[angle=0,width=8.6cm]{fig02.eps}](img117.png) |
![\includegraphics[angle=0,width=8.6cm]{fig02.eps}](img124.png) |
Next, we illustrate the problem of eliminating poorly determined
model parameters, as explained in Eq. (14). Figure
4 shows the singular values obtained by fitting
the second-, third-, and fourth-order models to the metadata. When the third- and
fourth-order polynomials are used in the fit, and
the maximum numbers of parameters is kept in Eq. (14), a number
of parameters become ill defined. This happens because some singular
values of matrix ![]() become extremely small.
As a result three smallest singular values of the matrix
become extremely small.
As a result three smallest singular values of the matrix ![]() must be
eliminated when the third-order polynomials are used in the fits to the metadata.
Similarly, the
must be
eliminated when the third-order polynomials are used in the fits to the metadata.
Similarly, the ![]() smallest singular values have to be eliminated for fourth order polynomials.
The extreme smallness of the singular values is a direct result
of some redundancy in the model parameters. This is obviously the
case in Fig. 1 for those rectangles where the numbers of
experimental data are small.
smallest singular values have to be eliminated for fourth order polynomials.
The extreme smallness of the singular values is a direct result
of some redundancy in the model parameters. This is obviously the
case in Fig. 1 for those rectangles where the numbers of
experimental data are small.
![\includegraphics[angle=0,width=8.6cm]{fig02.eps}](img114.png) |
As can be seen from Fig. 5, even more unimportant parameters could be eliminated from the fits without losing a significant amount of fit quality. If the second- or third-order polynomials are used to represent the shell effects, only about 60% of the independent uncorrelated model parameters (out of 39 or 80, respectively) are relevant and the remaining 40% do not contribute significantly to the fit, and can be safely removed. For the fourth-order (exact) model this is not the case, and many more parameters (about 85% of 136) are required to go down to the value of the rms deviation equal to 0.1MeV, corresponding to the Gaussian noise in the metadata.
![\includegraphics[width=11cm]{fig06.eps}](img118.png) |
Figures 6 and 7 present results of fits performed
for different choices of weights ![]() , defined in
Eq. (25). We first observe that fits of the
fourth-order (exact) model give results that are entirely independent
of weights. For
, defined in
Eq. (25). We first observe that fits of the
fourth-order (exact) model give results that are entirely independent
of weights. For ![]() , values of fitted parameters and their
error estimates are given in Table 1. Small differences
between the fitted values and values defining the metadata, and small
values of errors, illustrate the quite small impact of the 0.1MeV
Gaussian noise included in the metadata.
, values of fitted parameters and their
error estimates are given in Table 1. Small differences
between the fitted values and values defining the metadata, and small
values of errors, illustrate the quite small impact of the 0.1MeV
Gaussian noise included in the metadata.
The situation is drastically different for fits of the inaccurate models.
Here the values of the fitted parameters, shown in Fig. 6, are
not only quite different form the exact ones, but also rather
strongly depend on the choice of weights. It is clear that the weights
strongly affect the balance between the volume and surface
parameters. For weights giving greater importance to heavy nuclei
(![]() ), all absolute values of volume and surface parameters
decrease. The effect is particularly large for the surface symmetry
parameter
), all absolute values of volume and surface parameters
decrease. The effect is particularly large for the surface symmetry
parameter
![]() , which for the second-order model
decreases from about 9MeV at
, which for the second-order model
decreases from about 9MeV at ![]() to nearly zero at
to nearly zero at
![]() .
.
![\includegraphics[width=11cm]{fig07.eps}](img122.png) |
Variations of parameters, seen in Fig. 6, are much larger than their error estimates shown in Fig. 7. It means that the standard way of estimating errors, Eq. (19), may give significantly overoptimistic results. We stress here once again that the obtained variations in the LD parameters are induced by imperfect descriptions of shell effects only. One can say that such imperfections do contain smooth particle-number dependencies, which are then captured by the fitting procedure and get transferred to values of the LD parameters.
One can, in principle, argue that macroscopic (LD) and microscopic (shell) effects should not be mixed, but rather should be fitted separately to avoid cross-talk effects described above. This is certainly possible in macroscopic-microscopic models [6] that use separate expressions and/or methods to describe these two features of the mass surface. However, such separation induces ambiguities on its own, see e.g. Ref. [25], and, moreover, it cannot be realized in self-consistent methods, which describe the LD and shell effects by the same set of parameters.
![\includegraphics[angle=0,width=8.6cm]{fig02.eps}](img115.png) |
In Figs. 8 and 9 we show the confidence intervals and residuals, Eqs. (22) and (26), respectively, of the binding energies predicted in lead isotopes. For nuclides used in the fit (the range denoted by dotted vertical lines), confidence intervals and residuals obtained for the fourth-order (exact) model nicely reproduce the 0.1MeV Gaussian noise included in the metadata.
The situation is quite different for the inaccurate models, which correspond to fitting the second- or third-order polynomials. In lead isotopes, residuals of the third-order model are still quite small, well below the rms deviation of 1.0MeV, which is the value characterizing this fit. It simply means that for these observables, the model performs quite nicely. However, the confidence intervals tell us that the quality of the model even in lead nuclei is not that great as suggested by small residuals. For the second-order model, residuals become quite high but the confidence intervals indicate that the quality of the model does not, in fact, deteriorate. Confidence intervals and residuals give us diverging evaluations of the quality of the models, because the former represent global characteristics, which depend only on the standard deviations of the parameters, while the latter illustrate only local properties of the models.
An interesting property of the confidence intervals is the fact that, for nuclei outside the fit, the confidence intervals quickly increase, independently of the complexity of the model. This result is in accordance with results obtained within realistic nuclear mass models, whose predictions (for nuclei outside the fit) deviate greatly from each other. On the one hand, such an increase of the confidence intervals is a reflection of poor predictivity of models when they are extrapolated to exotic nuclei. On the other hand, the confidence intervals simply quantify this uncertainty of extrapolation and constitute precise measures of the fact that such extrapolations must be uncertain. This is so because the model parameters are rather loosely defined by the metadata, and therefore, important information is missing from the models.
The discontinuity of confidence intervals at ![]() is an artifact
of the model, which uses different parameters in rectangles delimited
by magic numbers, see Fig. 1. Note that the model ensures
the continuity of binding energies, but the confidence intervals need
not be continuous.
is an artifact
of the model, which uses different parameters in rectangles delimited
by magic numbers, see Fig. 1. Note that the model ensures
the continuity of binding energies, but the confidence intervals need
not be continuous.
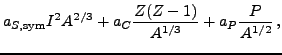
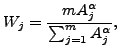
![\includegraphics[angle=0,width=8.6cm]{fig02.eps}](img125.png)